Chan-Hung YuHello! My name is Chan-Hung Yu. I am a PhD student at National Taiwan University (NTU). I am a member of the Robot Learning Lab, advised by Prof. Shao-Hua Sun. My research interests include Large Language Models, Reinforcement Learning, Programming Languages, Robotics, and Model-based RL. Beyond my academic pursuits, I enjoy anime, music, and video games. Email / GitHub / Google Scholar / Twitter / LinkedIn |
|
PublicationsI'm interested in machine learning, large language models, and reinforcement learning. |
|
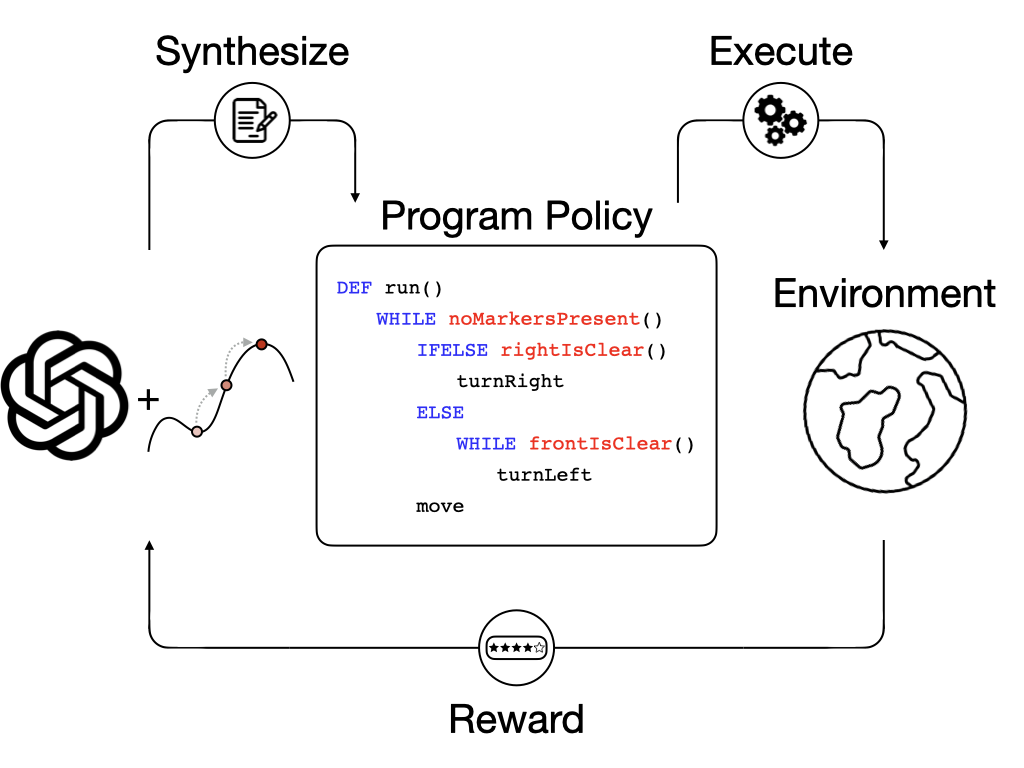
Synthesizing Programmatic Reinforcement Learning Policies with Large Language Model Guided SearchMax Liu*, Chan-Hung Yu*, Wei-Hsu Lee, Cheng-Wei Hung, Yen-Chun Chen, Shao-Hua Sun ICLR 2025 arxiv / code We address the challenge of LLMs’ inability to generate precise and grammatically correct programs in domain-specific languages (DSLs) by proposing a Pythonic-DSL strategy — an LLM is instructed to initially generate Python codes and then convert them into DSL programs. To further optimize the LLM-generated programs, we develop a search algorithm named Scheduled Hill Climbing, designed to efficiently explore the programmatic search space to improve the programs consistently. |
|
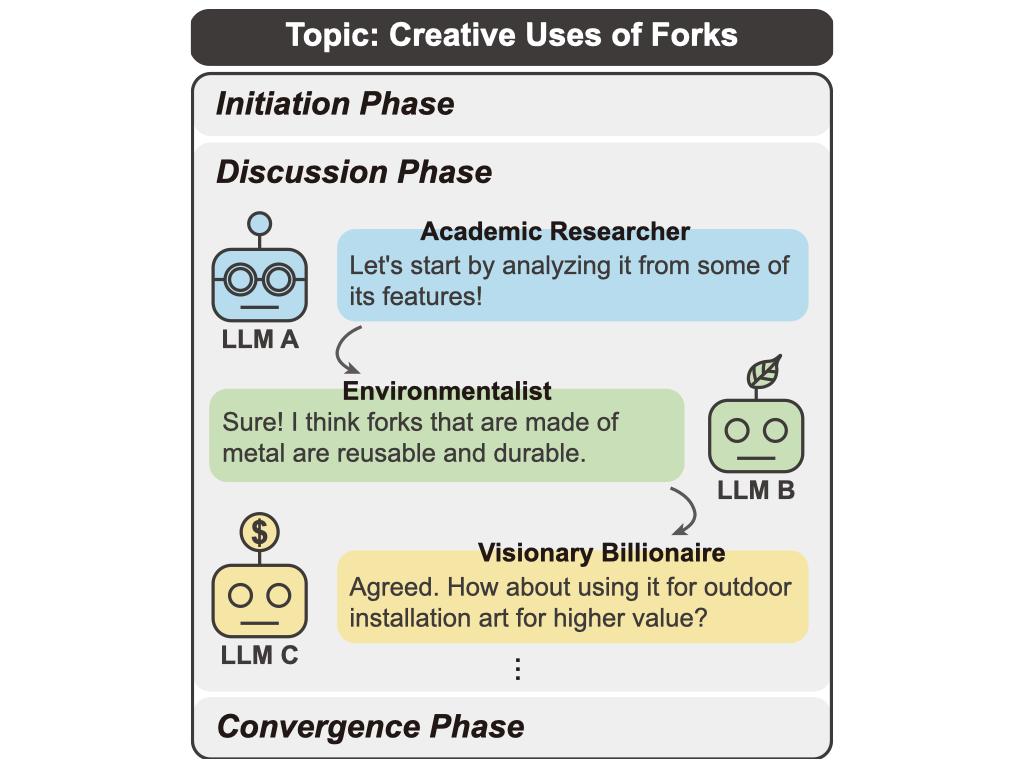
LLM Discussion: Enhancing the Creativity of Large Language Models via Discussion Framework and Role-PlayLi-Chun Lu*, Shou-Jen Chen*, Tsung-Min Pai, Chan-Hung Yu, Hung-yi Lee, Shao-Hua Sun COLM 2024 arxiv / code Large language models (LLMs) have shown exceptional proficiency in natural language processing but often fall short of generating creative and original responses to open-ended questions. To enhance LLM creativity, our key insight is to emulate the human process of inducing collective creativity through engaging discussions with participants from diverse backgrounds and perspectives. To this end, we propose LLM Discussion, a three-phase discussion framework that facilitates vigorous and diverging idea exchanges and ensures convergence to creative answers. Moreover, we adopt a role-playing technique by assigning distinct roles to LLMs to combat the homogeneity of LLMs. |
|
Design and source code from Jon Barron's website |